21.09.28 - 웹 개발 입문 32일차
Q. 과제풀이
다음에서 요구하는 데이터를 조회하시오.
1. 유통기한이 2021년인 제품을 출력
2. 여름(6,7,8)월에 생산된 과자 목록을 출력
3. 과자와 사탕 중에서 유통기한이 1년 이하인 제품의 목록을 출력
4. 최근 2년간 생산된 제품의 목록을 출력(730일 전부터 지금까지)
-- 1.
select * from product where extract(year from expire) = 2021;
select * from product where
expire >= to_date('20210101000000', 'YYYYMMDDHH24MISS')
and
expire <= to_date('20211231235959', 'YYYYMMDDHH24MISS');
select * from product where
expire between to_date('20210101000000', 'YYYYMMDDHH24MISS')
and to_date('20211231235959', 'YYYYMMDDHH24MISS');
select * from product where expire like '21%';--비추천
select * from product where instr(expire, '21') = 1;--비추천
-- to_char() : 문자열이 아닌 데이터를 문자열화 시키는 명령(숫자, 날짜 ---> 문자열)
-- 형식 : to_char(날짜객체, 변환형식)
select to_char(expire, 'YYYY-MM-DD') from product;r
select * from product where to_char(expire, 'YYYY-MM-DD') like '2021%';
select * from product where instr(to_char(expire, 'YYYY-MM-DD'), '2021') = 1;
-- 2.
select * from product
where type = '과자'
and extract(month from made) = 6 or extract(month from made) = 7 or extract(month from made) = 8;
select * from product where type = '과자' and extract(month from made) in (6, 7, 8);
select * from product where type = '과자' and extract(month from made) between 6 and 8;
select * from product where type = '과자' and extract(month from made) >= 6 and extract(month from made) <= 8;
select * from product where type = '과자' and made like '%/06/%' or made like '%/07/%' or made like '%/08/%';--비추천
select * from product where type = '과자'
and to_char(made, 'YYYY-MM-DD') like '%-06-%' or made like '%-07-%' or made like '%-08-%';
select * from product where type = '과자'
and regexp_like(to_char(made, 'YYYY-MM-DD'), '-0[678]-');
-- 3.오라클에서는 date끼리 계산이 가능하며 계산결과가 일단위로 나온다.
select * from product where type = '과자' or type = '사탕';
select * from product where type in ('과자', '사탕');
select expire - made from product where type in ('과자', '사탕');
select * from product where type in ('과자', '사탕') and expire - made <= 365;
select no, name, type, price, made, expire, expire-made "유통기한" from product
where type in ('과자', '사탕') and expire - made <= 365;
select product.*, expire-made "유통기한" from product
where type in ('과자', '사탕') and expire - made <= 365;
select product.*, expire-made "유통기한" from product
where type in ('과자', '사탕') and (expire - made) / 365 <= 1;
-- 4.
select product.*, sysdate-made from product where sysdate-made <= 730;--730일전(2년전)
select product.*, sysdate-made from product where (sysdate-made) / 365 <= 2;--2년전
select product.*, sysdate-made from product where sysdate-made <= 30;--30일전
select product.*, sysdate-made from product where sysdate-made <= 5 / 24 / 60;--5분전
데이터베이스 - 오라클 함수
듀얼 테이블(dual table)
- 작업을 수행하다보면 테이블이 없거나 처리가 어려운 경우가 발생
- ex : 임시 계산 , 여기서 조금 저기서 조금 가져와서 보여줘야 하는 경우
- 듀얼 테이블은 만드는것이 아니라 내장되어 있는 테이블
- select * from dual;
1234 + 5678 의 결과를 출력
select 1234 + 5678 from dual;= 6912
단일 행 함수(Single-Row Function) : 하나의 입력으로 하나의 결과가 나오는 함수
문자열 덧셈
select concat('안녕','하세요') from dual;
select '안녕' || '하세요' from dual;
select * from product where name like concat('바', '%');
select * from product where name like '%' || '바' || '%';= 안녕하세요= 안녕하세요= 스크류바= 스크류바, 바나나킥
영문자 변환
select upper('Hello') from dual; -- 대문자로만 표시
select lower('Hello') from dual; -- 소문자로만 표시
select * from product where name = '바나나킥';
select * from product where lower(name) = lower('바나나킥'); -- 모두 대문자로 검사
select * from product where upper(name) = upper('바나나킥'); -- 모두 소문자로 검사= HELLO= hello
앞글자만 대문자로 변환
select initcap('hello java') "결과" from dual;= Hello Java
문자열 자르기
select substr('ABCDEFG', 2) "결과" from dual;-- 2번째부터 잘라내라
select substr('ABCDEFG', 2, 3) "결과" from dual;-- 2번째부터 3글자 잘라내라= BCDEFG
= BCD
문자열 치환
select replace('오늘 점심은 치킨이다!', '치킨', '중국집') from dual;= 오늘 점심은 중국집이다!
NVL : null을 치환
select nvl(null, 'hello') from dual;
select nvl('hi', 'hello') from dual;= hello
= hi
문자열 길이 계산
select length('ABCDEFG') "길이" from dual;= 7
집계 함수 : 주어진 데이터를 취합하여 결과를 만들어내는 함수
(ex) 가장 비싼 상품의 가격, 모든 회원의 포인트 합계
- 최대, 최소, 합계, 평균, 개수

select max(price) "최대가격" from product;
select min(price) "최소가격" from product;
select sum(price) "합계" from product;
select avg(price) "평균" from product;
select count(price) "개수" from product;
select count(distinct price) "개수" from product;
select count(member_email) "회원수" from member; -- 잘못된 표현
select count(*) "개수" from product;
select count(*) "회원수" from member;= 3000
= 900
= 15100
= 1510
= 10
= 7
= 0
= 10
= 1
데이터베이스 - 서브쿼리
Q : 가장 비싼 상품의 이름을 조회
- 필터링 조건에 집계함수를 사용할 수 없다.
- 따라서 집계함수를 먼저 실행시키고 그 결과를 이용하여 필터링을 수행
select * from product where price = (select max(price) from product);
가격이 제일 저렴한 상품의 이름을 출력
select name from product where price = (select min(price) from product);= 마이쮸
포인트가 가장 적은 회원의 숫자
가장 최근에 가입한 회원의 모든정보
select count(*) "포인트가 적은 회원 수" from member
where member_point = (select min(member_point) from member);
select * from member where member_join = (select max(member_join) from member);= 1
= testuser1 testuser1 ㄴㅇㄴ123 99/01/10 010-1234-1234 21/09/27 100 준회원
정렬(Sort)
- 데이터를 원하는 목적에 맞게 나열하는 작업
- order by 항목 asc 내림차순 / desc 오름차순
상품을 가격순으로 조회(price asc)
상품을 이름순으로 조회(name asc)
상품을 가격 -> 이름 -> 번호순으로 조회
2020년에 제조된 상품을 최신순으로 조회(정렬은 제일 마지막에 해야한다)
select * from product order by price asc;
select * from product order by name asc;
select * from product order by price asc, name asc, no asc;
select * from product order by price desc, name asc, no asc;
select * from product where extract(year from made) = 2020 order by made desc;
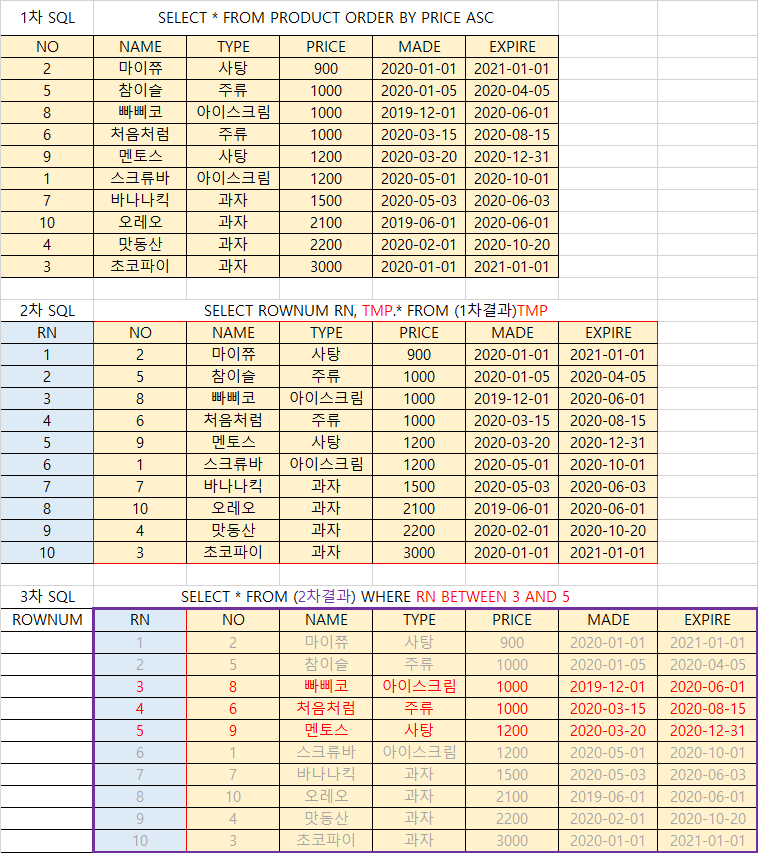
데이터베이스 - Top N Query
Top N Query
- 데이터를 원하는 개수, 범위만큼 끊어서 조회하는 구문 작성 방식
- 사례 : Top 3, Top 100, 페이지네이션(Pagination)
- rownum이 필요 : 결과집합의 데이터에 순서대로 부여되는 행번호(무조건 1부터 시작)
product 테이블에 rownum을 추가하여 조회
select rownum, product.* from product;
문제점 : 항목이 먼저 해석되기 때문에 rownum이 부여된 상태로 정렬이 되어 의미가 없어진다.
select rownum, product.* from product order by price asc;
1차 해결 : 서브쿼리를 이용하여 선 정렬 수행 후 rownum 부여
select rownum, TMP.* from (select * from product order by price asc)TMP;
Q. 가격이 싼제품 Top 3
select rownum, TMP.* from (select * from product order by price asc)TMP where rownum <= 3;
Q. 가격이 비싼제품 Top 5
select rownum, TMP.* from (select * from product order by price desc)TMP where rownum <= 5;
Q. 가장 최근에 만든 제품 Top 3
select rownum, TMP.* from (select * from product order by made desc)TMP where rownum between 1 and 3;
Q3. 가격이 비싼제품 3등부터 5등까지
select rownum, TMP.* from (select * from product order by price desc)TMP where rownum between 2 and 5;문제점 : ROWNUM을 부여하면서 조회할 경우 1부터 시작하는 경우만 조회할 수 있다.(중간조회가 불가능)
2차 해결 : ROWNUM을 다 부여해놓고 나중에 조건으로 처리
select * from (2차결과) where rownum between 3 and 5;
rownum은 select를 할 때 생성되는 값이므로 원하는 값을 "별칭"으로 특정해줄 필요가 있다.
select * from (select rownum rn, TMP.* from (select * from product order by price desc)TMP)
where rn between 3 and 5;
select * from (select rownum rn, TMP.* from ( ? )TMP)where rn between (?) and (?);
--> 물음표 자리만 바꿔주면 공식처럼 사용 할 수 있다
- Top N Query 과정
데이터베이스 - 그룹 쿼리
Group Query
- 그룹별로 데이터를 조회할 필요가 있을 경우 사용
- ex : Product 테이블에서 상품분류별 개수/합계/평균/최대/최소 와 같은 작업을 할 때 사용
- ex : 월별, 일별, 연도별, ...
- 집계 함수들을 이용하여 그룹별로 구분하여 정보를 획득하는 것이 목표
- 어떤 조건으로 그룹을 지을 것인지 명시해야 한다.
- 형식 : group by 항목 [having 항목조건]
타입별로 묶어서 타입명을 출력
select distinct type from product;--타입을 중복제거해서 출력(추가계산이 불가능)
select type from product group by type;--타입별로 묶어서 타입명을 출력(추가계산이 가능)
타입별 개수를 많은 순서로 정렬
select type, count(*) from product group by type order by count(*) desc;
select type, count(*) "개수" from product group by type order by "개수" desc;
타입별 합계를 큰순서부터 정렬
select type, sum(price) from product group by type order by sum(price) desc;
select type, sum(price) "합계" from product group by type order by "합계" desc;
최근 제조일자로 정렬
select type, max(made) from product group by type;
select type, max(made) "제조일자" from product group by type order by "제조일자" desc;
Q. 구글 스프레드시트를 참고하여 테이블을 구성하고 그룹 쿼리를 작성하여 실행하세요.
https://docs.google.com/spreadsheets/d/1VFopsxOPNjKTsMKtXvV8zQwrrCdULCFz9uMUe4GPm9M/edit?usp=sharing
1. 학생별 평균점수를 구하여 출력
2. 과목별 평균점수를 구하여 출력
3. 평가유형별 평균점수를 구하여 출력
4. 학생별 최고, 최저점을 구하여 출력
5. 과목별 최고, 최저점을 구하여 출력
6. 유형별 최고, 최저점을 구하여 출력
7. 과목별 60점 미만 학생의 수를 구하여 출력
8. 과목별 90점 이상 학생의 수를 구하여 출력
9. 평균이 높은 학생을 3등까지만 출력
-- 테이블 생성
create table exam(
exam_id number primary key,
student varchar(21) not null,
subject varchar2(60) not null,
type varchar2(60) not null,
score number(3) not null check(score between 1 and 100)
);
create sequence exam_seq;
-- 데이터 추가
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '피카츄', '프로그래밍언어활용', '서술형', 55);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '피카츄', '프로그래밍언어활용', '문제해결시나리오', 95);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '피카츄', '네트워크프로그래밍구현', '서술형', 60);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '피카츄', '네트워크프로그래밍구현', '평가자체크리스트', 51);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '라이츄', '프로그래밍언어활용', '서술형', 80);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '라이츄', '프로그래밍언어활용', '문제해결시나리오', 52);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '라이츄', '네트워크프로그래밍구현', '서술형', 58);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '라이츄', '네트워크프로그래밍구현', '평가자체크리스트', 80);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '파이리', '프로그래밍언어활용', '서술형', 54);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '파이리', '프로그래밍언어활용', '문제해결시나리오', 81);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '파이리', '네트워크프로그래밍구현', '서술형', 44);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '파이리', '네트워크프로그래밍구현', '평가자체크리스트', 76);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '꼬부기', '프로그래밍언어활용', '서술형', 100);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '꼬부기', '프로그래밍언어활용', '문제해결시나리오', 60);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '꼬부기', '네트워크프로그래밍구현', '서술형', 51);
insert into exam(exam_id, student, subject, type, score) values(exam_seq.nextval, '꼬부기', '네트워크프로그래밍구현', '평가자체크리스트', 72);
commit;
select * from exam;
--1. 학생별 평균점수를 구하여 출력
select student "학생", avg(score) "평균" from exam group by student;
select student "학생", avg(score) "평균" from exam group by student order by "평균" desc;
--2. 과목별 평균점수를 구하여 출력
select subject "과목", avg(score) "평균" from exam group by subject;
select subject "과목", avg(score) "평균" from exam group by subject order by "평균" desc;
--3. 평가유형별 평균점수를 구하여 출력
select type "유형", avg(score) "평균" from exam group by type;
select type "유형", avg(score) "평균" from exam group by type order by "평균" desc;
-- 추가 : 과목, 유형별 평균 출력
select subject "과목", type "유형", avg(score) "평균" from exam group by subject, type;
select subject "과목", type "유형", avg(score) "평균" from exam group by subject, type order by "평균" desc;
select subject "과목", type "유형", avg(score) "평균" from exam group by subject, type order by "과목" asc, "유형" asc;
--4. 학생별 최고, 최저점을 구하여 출력
select student "이름", max(score) "최고점", min(score) "최저점", max(score) - min(score) "차이" from exam group by student;
select student "이름", max(score) "최고점", min(score) "최저점", max(score) - min(score) "차이" from exam group by student order by "차이" desc;
--5. 과목별 최고, 최저점을 구하여 출력
select subject "과목", max(score) "최고점", min(score) "최저점", max(score) - min(score) "차이" from exam group by subject;
select subject "과목", max(score) "최고점", min(score) "최저점", max(score) - min(score) "차이" from exam group by subject order by "차이" desc;
--6. 유형별 최고, 최저점을 구하여 출력
select type "유형", max(score) "최고점", min(score) "최저점", max(score) - min(score) "차이" from exam group by type;
select type "유형", max(score) "최고점", min(score) "최저점", max(score) - min(score) "차이" from exam group by type order by "차이" desc;
--7. 과목별 60점 미만 학생의 수를 구하여 출력
select subject "과목", count(*) "인원수" from exam group by subject;--과목별 응시 인원수
select subject "과목", count(*) "인원수" from exam where score < 60 group by subject;--과목별 60점 미만 인원수
--8. 과목별 90점 이상 학생의 수를 구하여 출력
select subject "과목", count(*) "인원수" from exam group by subject;--과목별 응시 인원수
select subject "과목", count(*) "인원수" from exam where score >= 90 group by subject;--과목별 90점 이상 인원수
--9. 평균이 높은 학생을 3등까지만 출력
select * from (
select rownum "순위", TMP.* from (
select student "학생", avg(score) "평균" from exam group by student order by "평균" desc
)TMP
) where "순위" between 1 and 3;
-- 추가 : 점수대별(10점단위) 학생 분포 현황
select floor(score / 10), count(*) from exam group by floor(score / 10);
select trunc(score / 10), count(*) from exam group by trunc(score / 10);
select trunc(score / 10) "점수구간", count(*) "인원수" from exam group by trunc(score / 10);
select trunc(score / 10) || '0' "점수구간", count(*) "인원수" from exam group by trunc(score / 10);
select trunc(score / 10) || '0' "점수구간", count(*) "인원수" from exam group by trunc(score / 10) order by "인원수" desc;
select trunc(score / 10) || '0' "점수구간", count(*) "인원수" from exam group by trunc(score / 10) order by "점수구간" asc;
select to_number(trunc(score / 10) || '0') "점수구간", count(*) "인원수" from exam group by trunc(score / 10) order by "점수구간" asc;
그룹 조건 ( HAVING )
전체 평균이 70점 미만인 학생만 조회
select student, avg(score) from exam group by student having avg(score) < 70;--정상 코드(그룹 필터링)
데이터베이스 - 복합키(Composite Key)
Primary key(기본키, 고유키)
= 테이블의 컬럼을 대표하는 역할
= 테이블에 1개만 설정되어야 한다
ex : 학생정보를 저장(학년, 반, 번호, 이름)
1. 학번이라는 고유항목을 만들어서 기본키로 관리
2. 학년 + 반 + 번호를 조합해서 기본키로 관리(복합키 = composite key)
create table student(
grade number(1),
class number(1),
no number(2),
name varchar2(21),
primary key(grade, class, no)
-- unique(grade, class, no)
);
insert into student(grade, class, no, name) values(1, 1, 1, '피카츄');
insert into student(grade, class, no, name) values(1, 1, 2, '라이츄');
insert into student(grade, class, no, name) values(2, 2, 5, '파이리');
insert into student(grade, class, no, name) values(2, 2, 5, '꼬부기'); --기본키(복합키) 위반
commit;